2020 신입 개발자 카카오 블라인드 시험을 치다가,
문자열 처리에 대한 자료구조를 알게 되었다.
Trie 자료구조에 대한 다음과 같은 모습으로 생겼다.
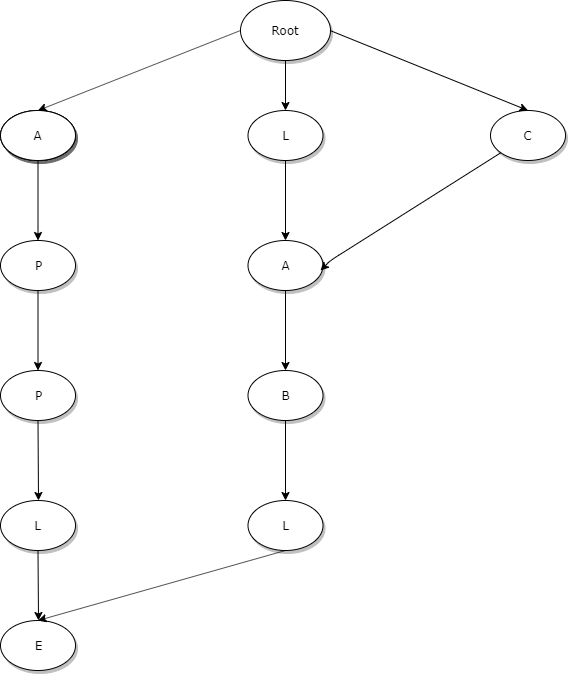
위에 보면, APPLE, LABLE, CABLE이라는 단어를 넣은 것이다.
왜 굳이, Trie 자료구조를 사용해야 하는지를 생각해보자.
특정 문자열을 벡터에서 순차적으로 탐색하면, 최대 문자열의 갯수만큼 걸리게 된다.
하지만 Trie 자료구조를 사용하면, 문자열의 길이만큼의 탐색 시간이 걸린다.
즉, 많은 문자열속에서 특정한 문자열을 찾기 위해서는 Trie만한 자료구조가 없다.
Trie 자료 구조를 사용하지 않으면, 카카오 블라인드 2020 기출문제 효율성을 통과할 수 없게끔 설계되어 있다.
Trie 자료 구조를 몰랐을 때 사용했던 방법은,
문자열을 일일이 나누어서, Map 자료 구조에 넣었었다. 이 방식으로, 효율성 2번만 시간 초과가 뜨고 나머지는 통과할 수 있었다.
문자열을 일일이 나눈다는 것이 무슨 말이냐면,
Words 자료구조에 apple이 들어있다고 하면,
a????, ap???, app??, appl? 식으로 문자열들을 생성하고 map 자료구조에 넣는 것이다.
위에 방식을 시간복잡도 개념으로 접근해보자면,
a를 만들 때, 인덱스 탐색 1회,
ap를 만들 때, 인덱스 탐색 2회,
app를 만들 때, 인덱스 탐색 3회,
appl를 만들 때, 인덱스 탐색 4회,
apple은 굳이 만들 필요가 없어서 생략했다.
즉, 1 + 2 + 3 + 4 + ... + n - 1 정도 인덱스 탐색이 필요하다.
하지만, Trie 자료구조를 사용하면 문자열 길이만큼의 인덱스 탐색만 필요하다.
위에 증명으로, Trie 자료구조가 필요한 이유가 설명되었을 것이다.
[자료구조 예제 코드]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
#include <iostream>
#include <cstring>
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
struct Trie {
bool finish;
Trie* next[26];
Trie() : finish(false) {
memset(next, 0, sizeof(next));
}
void insert(const char* key) {
if ((*key) == '\0') {
finish = true;
return;
};
int curr = (*key) - 'a';
if (!next[curr])
next[curr] = new Trie();
next[curr]->insert(key + 1);
}
bool find(const char* key) {
if ((*key) == '\0')
return true;
int curr = (*key) - 'a';
if (!next[curr])
return false;
return next[curr]->find(key + 1);
}
};
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
위에 코드를 문제에 따라서 응용해야 한다.
위 자료구조에서 필수적인 것은, 다음 노드를 가르킬 수 있는 구조체 포인터형 배열이 필요하다. 배열의 길이는 문제의 조건에 따라서 달라질 것이다. 위에서 26은 a-z의 알파벳 갯수를 의미한다.
또한, insert와 find 함수는 위의 구조체에 필수이다. 위의 함수들을 보고 완벽하게 이해할 수 있고, 안보고 코드를 짤 수 있을 정도면 충분히 문제에서 사용할 수 있다.
insert 함수에 대해서 조금 더 기초적으로 설명을 하자면,
매개변수로 가져오는 key는 문자열을 의미한다. key는 포인터 값으로, 문자열의 가장 앞에 위치하는 문자를 가르킨다.
이 부분이 이해가 되지 않으면, C++ 포인터 기초에 대해서 이해하는 것이 필요하다.
C++은, 문자열의 마지막을 구분하기 위해서 '\0'이 자동으로 삽입되게 된다. 그래서, 문자열의 마지막에 왔다면, 더 이상 insert 함수를 종료하게 된다.
(*key) - 'a'가 의미하는 것은, 아스키 코드값을 이용해서 배열에 넣기 위함이다. next 배열은 Trie 구조체의 포인터 배열이므로, 다음 노드를 가르킬 수 있는 자료구조이다. 만약에, 다음을 가르키는 Trie 구조체가 없다면, new Trie()를 통해서 생성하게 되고, insert 작업을 진행하게 된다.
find 함수에 대해서 기초적으로 설명을 하자면,
매개변수로 가져오는 key는 마찬가지로 문자열을 의미한다. 문자열의 모든 문자를 찾을 수 있고, \0' 마지막 문자에 도달했다면 true를 리턴한다.
그게 아니라면, 다음 노드를 가르키는 인덱스를 찾고, find 함수를 재귀적으로 호출한다.
위에 두 함수와 Trie 구조체 포인터형 배열을 이해한다면, 완벽하게 Trie 자료구조를 사용할 수 있다.
모두 화이팅!
'컴퓨터공학 > 자료구조' 카테고리의 다른 글
| 정렬별 시간복잡도를 생각해보자(Bubble Sort, Selection Sort, Insertion Sort, Quick Sort, Merge Sort, Heap Sort, Time Complexity) (0) | 2020.11.21 |
|---|---|
| 힙 트리란 무엇일까(Max, Min Heap Tree) (0) | 2020.11.20 |
| [JAVA] 알고리즘에서 자주 쓰이는 자료구조 정리(예제, 사용시기, 백준, 프로그래머스, 필수 자료구조) (0) | 2020.08.29 |
| [C++] 우선순위큐 구조체 사용하는 법, 알고리즘, 이론 (0) | 2020.01.25 |
| [C++] Set 자료구조 역순으로 자료 참조하기 (0) | 2019.10.05 |