 디스크 스케줄링(디스크 구조, 기법)
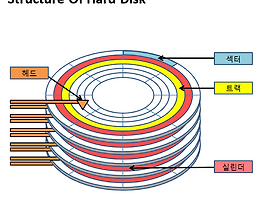
우선 디스크 스케줄링을 알아보기 전에, 실린더, 플래터, 헤더, 트랙, 섹터 등의 용어들에 대해서 정리하고 가자. 위의 그림이 가장 정확하게 하드 디스크를 설명했다. 모든 플래터에는 헤드가 모두 존재한다. 입력으로 주어지는 것들은 트랙 번호이다. 추가적으로, 하드디스크 구조를 눈으로 보고 싶은 분들을 위해서 유튜브 영상도 하나 링크한다. www.youtube.com/watch?v=NtPc0jI21i0 위의 영상을 보면서, 하드디스크 구조를 확실히 파악할 수 있을 것이다. 디스크 스케줄링은 주어진 트랙 번호들을 찾아가는 과정들을 의미하며, 이동 거리 비교를 통해서 각 상황에서 스케줄링의 우위를 판단하게 된다. FCFS(First Comes First Served) 스택과 동일하게, 선입 선출 구조 들어온 ..
디스크 스케줄링(디스크 구조, 기법)
우선 디스크 스케줄링을 알아보기 전에, 실린더, 플래터, 헤더, 트랙, 섹터 등의 용어들에 대해서 정리하고 가자. 위의 그림이 가장 정확하게 하드 디스크를 설명했다. 모든 플래터에는 헤드가 모두 존재한다. 입력으로 주어지는 것들은 트랙 번호이다. 추가적으로, 하드디스크 구조를 눈으로 보고 싶은 분들을 위해서 유튜브 영상도 하나 링크한다. www.youtube.com/watch?v=NtPc0jI21i0 위의 영상을 보면서, 하드디스크 구조를 확실히 파악할 수 있을 것이다. 디스크 스케줄링은 주어진 트랙 번호들을 찾아가는 과정들을 의미하며, 이동 거리 비교를 통해서 각 상황에서 스케줄링의 우위를 판단하게 된다. FCFS(First Comes First Served) 스택과 동일하게, 선입 선출 구조 들어온 ..
 N보다 작은 특정 수의 배수를 찾아보자[최대 공약수, 최소 공배수, 교집합, Ugly Number III]
## 접근방법 간단히 생각해보자, N보다 작은 2의 배수의 개수는 몇 개일까? 정답은, N / 2개이다. N / 2개가 된다는 사실은 자명하므로 증명은 생략하겠다. A와 B가 있을 때, 두 수의 최대 공약수는 얼마일까? GCD(A, B) = GCD(B, A % B)이다. 증명은 아래와 같다. GCD(A, B) = G일 때, GCD(B, A % B)의 최대공약수도 G일까? A = G * a B = G * b A = B * q + r A % B = r = A - B * q B = G * b r = A - B * q = G * a - G * b * q= G(a - bq) 으로 증명될 수 있다. 이제 최소 공배수에 대해서 알아보자, 최소 공배수는 두 수의 곱에다가 최대 공약수를 나눠주면 된다. LCM(A, B)..
N보다 작은 특정 수의 배수를 찾아보자[최대 공약수, 최소 공배수, 교집합, Ugly Number III]
## 접근방법 간단히 생각해보자, N보다 작은 2의 배수의 개수는 몇 개일까? 정답은, N / 2개이다. N / 2개가 된다는 사실은 자명하므로 증명은 생략하겠다. A와 B가 있을 때, 두 수의 최대 공약수는 얼마일까? GCD(A, B) = GCD(B, A % B)이다. 증명은 아래와 같다. GCD(A, B) = G일 때, GCD(B, A % B)의 최대공약수도 G일까? A = G * a B = G * b A = B * q + r A % B = r = A - B * q B = G * b r = A - B * q = G * a - G * b * q= G(a - bq) 으로 증명될 수 있다. 이제 최소 공배수에 대해서 알아보자, 최소 공배수는 두 수의 곱에다가 최대 공약수를 나눠주면 된다. LCM(A, B)..
 정렬별 시간복잡도를 생각해보자(Bubble Sort, Selection Sort, Insertion Sort, Quick Sort, Merge Sort, Heap Sort, Time Complexity)
Q. 정렬의 종류는 무엇이 있을까? 종류들을 나열하고, 간단하게 알고리즘에 대해서 설명하겠다. 오름 차순 정렬 기준으로 설명하겠다. 버블정렬 : 순차적으로 근접한 두 값을 비교하면서, 마지막에 거품(Bubble)처럼 하나의 값을 얻게 된다. 같은 과정으로 하나의 값들을 얻어보면 정렬할 수 있다. 선택정렬 : 선택정렬은 전체의 원소에서 가장 작은 값을 순차적으로 찾아가면서 정렬한다. 삽입정렬 : K번째 원소의 위치를 찾을 때, 1부터 K-1까지는 모두 정렬이 되어 있으므로, K -1번째부터 값을 비교하며 위치를 찾으면서 정렬한다. 퀵정렬 : 피벗을 선택하고, 피벗을 기준으로 왼쪽에는 피벗보다 작은 값이 오른쪽에는 피벗보다 큰 값이 오도록 한다. 재귀적으로 호출하며 모든 원소들을 정렬한다. 합병정렬 : 재귀..
정렬별 시간복잡도를 생각해보자(Bubble Sort, Selection Sort, Insertion Sort, Quick Sort, Merge Sort, Heap Sort, Time Complexity)
Q. 정렬의 종류는 무엇이 있을까? 종류들을 나열하고, 간단하게 알고리즘에 대해서 설명하겠다. 오름 차순 정렬 기준으로 설명하겠다. 버블정렬 : 순차적으로 근접한 두 값을 비교하면서, 마지막에 거품(Bubble)처럼 하나의 값을 얻게 된다. 같은 과정으로 하나의 값들을 얻어보면 정렬할 수 있다. 선택정렬 : 선택정렬은 전체의 원소에서 가장 작은 값을 순차적으로 찾아가면서 정렬한다. 삽입정렬 : K번째 원소의 위치를 찾을 때, 1부터 K-1까지는 모두 정렬이 되어 있으므로, K -1번째부터 값을 비교하며 위치를 찾으면서 정렬한다. 퀵정렬 : 피벗을 선택하고, 피벗을 기준으로 왼쪽에는 피벗보다 작은 값이 오른쪽에는 피벗보다 큰 값이 오도록 한다. 재귀적으로 호출하며 모든 원소들을 정렬한다. 합병정렬 : 재귀..




